程式功能
取出Java資料傳輸物件中,每個欄位和註解
Java物件檔案內容
public class ValueBean {
/**
* fieldA 的註解
*/
private String filedA;
// fieldB 的註解
private BigDecimal fieldB;
//getter & setter.....
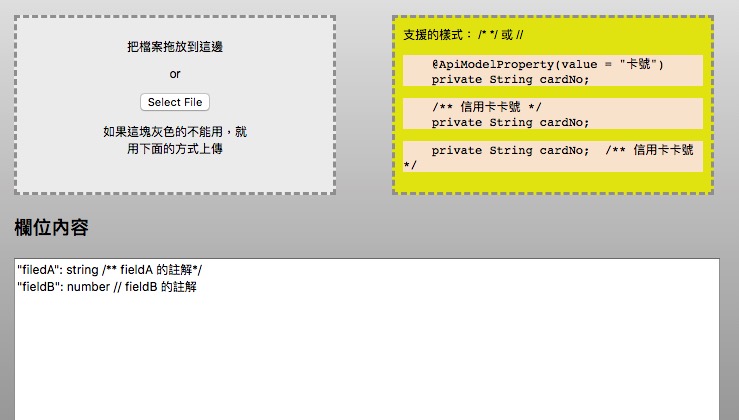
把ValueBean.java檔案拖拉到灰色上傳區塊後,取出欄位名稱及加上註解後顯示在「欄位內容」區塊
程式 beanParser.py
parseBeanField
程式進入點,傳入的參數是每一行程式(List)
def parseBeanField(rsFileContent):
""" 程式主進入點,
傳入字串List(java檔的每一行程式),
回傳拆解後的內容
"""
newLines = clearSymbols(rsFileContent)
prefixRegex = re.compile(r'^private\s(?!static)(.+)\s(.+)(;)(.*)')
resultList = []
for idx, line in enumerate(newLines):
mo = prefixRegex.search(line)
if mo is not None:
typeStr = lowerTypeName(mo.group(1))
fieldName = mo.group(2)
comment = getComment(idx, newLines)
resultList.append('"'+fieldName + '": '+ typeStr +' '+ comment)
return '\n'.join(resultList)
clearSymbols()
檢查該行程式是否為欄位註解混合,如果寫在同一行,把註解和field拆開
private String field; /* 這個是註解 */
拆開成這樣
/* 這個是註解 */
private String field;
def clearSymbols(rsFileContent):
""" """
newLines = []
commentReg = re.compile(r'(.+;)\s*(/\*(.*)\*/|//.*)')
for line in rsFileContent:
if not isLineEmpty(line):
line = line.replace('\n', '')
line = line.replace('\t', '')
line = line.strip()
mo = commentReg.search(line)
if mo is not None and mo.group(2) is not None:
#欄位混註解時,把註解內容取出放在欄位內容上一行
newLines.append(mo.group(2).strip())
newLines.append(mo.group(1).strip())
else:
line = removeDefault(line)
newLines.append(line)
return newLines
isLineEmpty
def isLineEmpty(line):
""" 檢查傳入內容是否為空白行 """
return len(line.strip()) < 1
removeDefault
如果欄位有寫預設值
private String field = "default";
把設值部分拿掉
private String field;
def removeDefault(line):
""" 若欄位有寫'='和預設值,進行移除 """
if '@ApiModelProperty' not in line:
if line.find('=') > -1:
line = line[:line.find('=')]+';'
if line.find(';') > -1:
if line[-2].isspace():
line = line[:-2]+';'
return removeDefault(line)
return line
lowerTypeName
把型態字串轉成小寫,如果是數值型態,全部換成number
def lowerTypeName(type):
primTypes = 'String,BigDecimal,Date,Integer,Boolean,boolean,int,double,long,Long'
numberTypes = 'bigdecimal,integer,int,double,double,long,Long'
if type in primTypes:
type = type.lower()
if type in numberTypes:
type = 'number'
return type
return type
getComment
如果是單行註解,直接回傳該行註解內容
def getComment(fieldIdx, lines):
""" 取得欄位註解 """
commentReg = re.compile(r'/\*(.*)\*/|//.*')
lineBefore = lines[fieldIdx-1]
mo = commentReg.search(lineBefore)
if mo is not None:
return mo.group()
elif '@ApiModelProperty' in lineBefore:
return '/**' + lineBefore.split('"')[-2] + '*/'
elif '*/' in lineBefore:
return getMultiLineComment(fieldIdx-1, lines)
else:
return '/** */'
getMultiLineComment
如果欄位的上一行只有 ‘*/’時,往回找最近的
def getMultiLineComment(endCommonentIdx, allLines):
""" 取得多行欄位註解 """
commentStartReg = re.compile(r'/\*(.*)')
commentAll = []
startIndex = 0;
for i in range( endCommonentIdx - 1, -1, -1) :
so = commentStartReg.search(allLines[i])
if so is not None:
startIndex = i
break
for i in range( startIndex, endCommonentIdx+1):
currLine = allLines[i];
if i !=startIndex and i != endCommonentIdx:
currLine = currLine.replace('*', '')
commentAll.append(currLine)
return ''.join(commentAll)
github:bean-comment-extractor